转载地址:
1. 前言
PCA : principal component analysis ( 主成分分析)
最近发现我的一篇关于PCA算法总结以及个人理解的博客的访问量比较高, 刚好目前又重新学习了一下PCA (主成分分析) 降维算法, 所以打算把目前掌握的做个全面的整理总结, 能够对有需要的人有帮助。 自己再看自己写的那个关于PCA的博客, 发现还是比较混乱的, 希望这里能过做好整理。 本文的所有总结参考了Andrew Ng的PCA教程, 有兴趣的可以自己学习。
上一篇关于PCA 的博客: , 在这篇博客中,有关于我最初在读研的时候关于PCA的认识, 但是不是很系统, 然后里面却给出了很多我总结的网络上的资料, 以及根据我个人使用的经验总结的感悟, 所以还是收到了很多的好评, o(∩∩)o...哈哈, 谢谢各位的支持。
@copyright by watkins.song ^_^
2. PCA的应用范围
PCA的应用范围有:
1. 数据压缩
1.1 数据压缩或者数据降维首先能够减少内存或者硬盘的使用, 如果内存不足或者计算的时候出现内存溢出等问题, 就需要使用PCA获取低维度的样本特征。
1.2 其次, 数据降维能够加快机器学习的速度。
2. 数据可视化
在很多情况下, 可能我们需要查看样本特征, 但是高维度的特征根本无法观察, 这个时候我们可以将样本的特征降维到2D或者3D, 也就是将样本的特征维数降到2个特征或者3个特征, 这样我们就可以采用可视化观察数据。
3. PCA原理简介
3.1 基础入门
这里我只给出在需要使用PCA的时候需要了解的最基本的PCA的原理, 了解这些原理后对于正常的使用没有问题, 如果想要深入了解PCA, 需要学习一些矩阵分析的知识, 更加详细的PCA算法请见wikipedia。
首先, 我们定义样本和特征, 假定有 m 个样本, 每个样本有 n 个特征, 可以如下表示:

由简到难, 先看一下从2D 降维到1D的比较直观的表示:
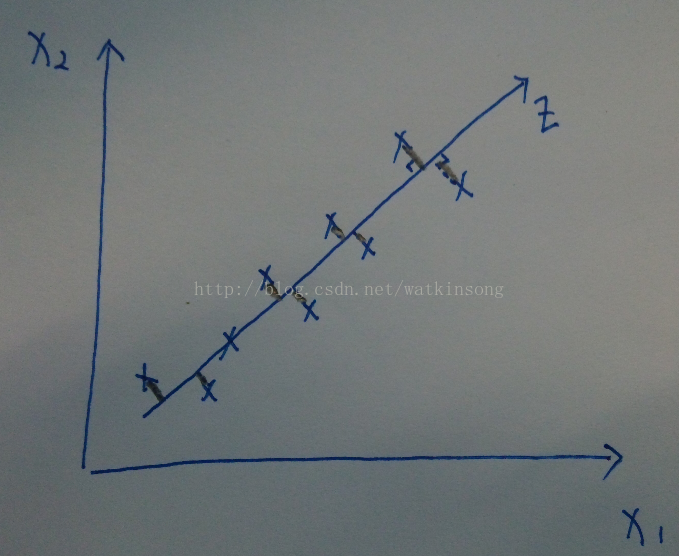
在上图中, 假设只有两个特征x1, x2, 然后需要降维到1D, 这个时候我们可以观察途中X所表示的样本点基本上分布在一条直线上, 那么就可以将所有的用(x1, x2)平面表示的坐标映射到图像画出的直线z上, 上图中的黑色铅笔线表示样本点映射的过程。
映射到直线Z后, 如果只用直线Z表示样本的空间分布, 就可以用1个坐标表示每个样本了, 这样就将2D的特征降维到1D的特征。 同样的道理, 如果将3D的特征降维到2D, 就是将具有3D特征的样本从一个三维空间中映射到二维空间。
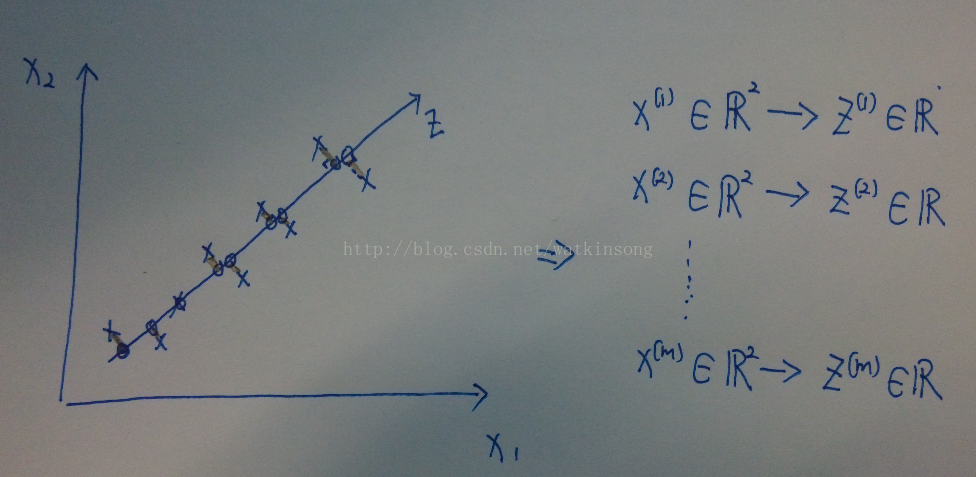
在上图中, 将所有的二维特征的样本点映射到了一维直线上, 这样, 从上图中可以看出在映射的过程中存在映射误差。
在上图中, 用圆圈表示了样本映射后的坐标位置。这些位置可以叫做近似位置, 以后还要用到这些位置计算映射误差。
因为在降维映射的过程中, 存在映射误差, 所有在对高维特征降维之前, 需要做特征归一化(feature normalization), 这个归一化操作包括: (1) feature scaling (让所有的特征拥有相似的尺度, 要不然一个特征特别小, 一个特征特别大会影响降维的效果) (2) zero mean normalization (零均值归一化)。
在上图中, 也可以把降维的过程看作找到一个或者多个向量u1, u2, ...., un, 使得这些向量构成一个新的向量空间(需要学习矩阵分析哦), 然后把需要降维的样本映射到这个新的样本空间上。
对于2D -> 1D 的降维过程, 可以理解为找到一个向量u1, u1表示了一个方向, 然后将所有的样本映射到这个方向上, 其实, 一个向量也可以表示一个样本空间。
对于3D -> 2D 的降维过程, 可以理解为找到两个向量u1, u2, (u1, u2) 这两个向量定义了一个新的特征空间, 然后将原样本空间的样本映射到新的样本空间。
对于n-D -> k-D 的降维过程, 可以理解为找到 k 个向量 u1, u2, ..., uk, 这k个向量定义了新的向量空间, 然后进行样本映射。
3.2 Cost Function
既然样本映射存在误差, 就需要计算每次映射的误差大小。 采用以下公式计算误差大小:

X-approx表示的是样本映射以后的新的坐标, 这个坐标如果位置如果用当前的样本空间表示, 维度和 样本X是一致的。
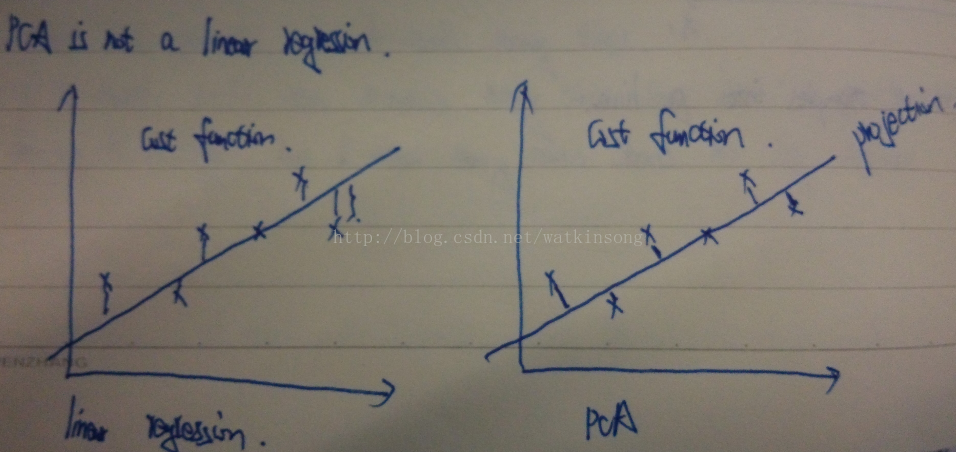
要特别注意, PCA降维和linear regression是不一样的, 虽然看上去很一致, 但是linear regression的cost function的计算是样本上线垂直的到拟合线的距离, 而PCA的cost function 是样本点到拟合线的垂直距离。 差别如下图所示:
3.3 PCA 计算过程
(A) Feature Normalization
function [X_norm, mu, sigma] = featureNormalize(X) %FEATURENORMALIZE Normalizes the features in X % FEATURENORMALIZE(X) returns a normalized version of X where % the mean value of each feature is 0 and the standard deviation % is 1. This is often a good preprocessing step to do when % working with learning algorithms. mu = mean(X); X_norm = bsxfun(@minus, X, mu); sigma = std(X_norm); X_norm = bsxfun(@rdivide, X_norm, sigma); end
(B) 计算降维矩阵


(C) 降维计算
获得降维矩阵后, 即可通过降维矩阵将样本映射到低维空间上。 降维公式如下图所示:
3.4 贡献率 (降维的k的值的选择)
在 这篇文章中, 很多人问了关于贡献率的问题, 这就是相当于选择k的值的大小。 也就是选择降维矩阵 U 中的特征向量的个数。

3.5 重构 (reconstruction, 根据降维后数据重构原数据), 数据还原
获得降维后的数据, 可以根据降维后的数据还原原始数据。
4. PCA的应用示例
貌似本页已经写的太多了, 所以这里示例另外给出。%% Initialization clear ; close all; clc fprintf('this code will load 12 images and do PCA for each face.\n'); fprintf('10 images are used to train PCA and the other 2 images are used to test PCA.\n'); m = 4000; % number of samples trainset = zeros(m, 32 * 32); % image size is : 32 * 32 for i = 1 : m img = imread(strcat('./img/', int2str(i), '.bmp')); img = double(img); trainset(i, :) = img(:); end %% before training PCA, do feature normalization mu = mean(trainset); trainset_norm = bsxfun(@minus, trainset, mu); sigma = std(trainset_norm); trainset_norm = bsxfun(@rdivide, trainset_norm, sigma); %% we could save the mean face mu to take a look the mean face imwrite(uint8(reshape(mu, 32, 32)), 'meanface.bmp'); fprintf('mean face saved. paused\n'); pause; %% compute reduce matrix X = trainset_norm; % just for convience [m, n] = size(X); U = zeros(n); S = zeros(n); Cov = 1 / m * X' * X; [U, S, V] = svd(Cov); fprintf('compute cov done.\n'); %% save eigen face for i = 1:10 ef = U(:, i)'; img = ef; minVal = min(img); img = img - minVal; max_val = max(abs(img)); img = img / max_val; img = reshape(img, 32, 32); imwrite(img, strcat('eigenface', int2str(i), '.bmp')); end fprintf('eigen face saved, paused.\n'); pause; %% dimension reduction k = 100; % reduce to 100 dimension test = zeros(10, 32 * 32); for i = 4001:4010 img = imread(strcat('./img/', int2str(i), '.bmp')); img = double(img); test(i - 4000, :) = img(:); end % test set need to do normalization test = bsxfun(@minus, test, mu); % reduction Uk = U(:, 1:k); Z = test * Uk; fprintf('reduce done.\n'); %% reconstruction %% for the test set images, we only minus the mean face, % so in the reconstruct process, we need add the mean face back Xp = Z * Uk'; % show reconstructed face for i = 1:5 face = Xp(i, :) + mu; face = reshape((face), 32, 32); imwrite(uint8(face), strcat('./reconstruct/', int2str(4000 + i), '.bmp')); end %% for the train set reconstruction, we minus the mean face and divide by standard deviation during the train % so in the reconstruction process, we need to multiby standard deviation first, % and then add the mean face back trainset_re = trainset_norm * Uk; % reduction trainset_re = trainset_re * Uk'; % reconstruction for i = 1:5 train = trainset_re(i, :); train = train .* sigma; train = train + mu; train = reshape(train, 32, 32); imwrite(uint8(train), strcat('./reconstruct/', int2str(i), 'train.bmp')); end fprintf('job done.\n');